잡담
대학에서 텐서플로우에 대한 과목이 있어 흥미가 생겨 수강신청했다. DOTS 자료를 정리하다 말고 이걸 하게 되긴했는데... 그만 둔건 아니고 시기상 일과 학업이 겹쳐 잠시 일시정지 상태라 봐야겠다. 이럴 땐 개인 자료 정리용으로 블로그를 쓰는게 참 다행이다. 다른 전문적인 블로거 분들은 글 작성에 신중할 수 밖에 없을테니
인공지능(A.I.)
정의
인공지능(Artificial Intelligence, 이하 AI)란 인간처럼 학습하고 생각할 수 있는 컴퓨터 시스템을 말한다.
영화에서 보면 정말 사람처럼 사고하고 사람처럼행동하는 것이 대표적으로 생각하는 인공지능의 뜻이라 볼 수 있다.
하지만 현실적인 문제로 이 수준에 달하는 인공지능은 아직 불가하여 인공지능을 조금 더 분류하고 나아가 다른 방법도 생각해내고있다.
종류
AI의 종류는 약, 강, 초 세 단계로 분류한다.
약 인공지능(Narrow A.I.)
약 인공지능은 구글의 알파고, 기계 자동번역기, 스팸메일 필터링과 같이 하나의 목적을 띄고 학습하고 판단할 수 있는 인공지능을 의미한다. 사진을 분류하는 것을 예시로 둘 때 사진이 핫도그가 있는 사진인지 분류한 것을 배운 인공지능은 고양이나 햄버거와 같은 다른 것을 인지할 수 없다. 즉, 한 분야에 대해서만 판단이 가능하기에 약(좁은, Narrow) 인공지능이라 부른다.
강 인공지능(General A.I.)
강 인공지능은 특정 분야 뿐 아니라, 모든 분야에서 인간과 동등하거나 그 이상의 능력을 가진 인공지능을 말한다. 즉, 인간의 단계를 뛰어넘어 인간 처럼 학습하고 인간 보다 빠르게 해내는 인공지능으로 영화에 나오는 사람처럼 말하는 인공지능이 이 것에 해당한다.
초 인공지능(Super A.I.)
초 인공지능은 인간을 아득히 넘어선 지능으로 스스로를 지속적으로 개선해 나갈 수도있으며, 다른 인공지능을 만들 수도 있는 수준의 인공지능이다. 흔히 인공지능이 세상을 지배하게 될 것이다 라는 말은 이 것에 해당한다.
머신 러닝(Machine Learning)
정의
머신 러닝은 경험을 통해 자동으로 개선하는 컴퓨터 알고리즘으로 인공지능의 한 분야로 간주된다.
일반적으로 행동 하나하나를 코드로 명시하는 방식과 달리 기계가 데이터로부터 학습하여 동작할 수 있도록 알고리즘을 개발하는 연구 분야로 보면 된다.
종류
머신 러닝은 크게 세가지로 나눈다.
지도학습(Supervised Learning)
입력값과 결과값(정답)을 같이 주고 학습을 시키는 방법으로, 분류와 회귀 등 여러가지 방법에 쓰인다. 지도학습의 학습모델은 SVM(Support Vector Machine), 결정트리(Decision Tree), 회귀모델 등이 있다.
비지도학습(Unsupervised Learning)
결과값(정답) 없이 입력값만을 이용하여 학습을 시킨다.
강화학습(Reinforcement Learning)
결과값 대신 어떤 일을 잘했을 때 보상(Reward)을 주는 방법을오 학습을 시킨다. 강화학습은 현재의 상태(State)에서 어떤 행동(Action)을 취하는 것이 최적인지를 학습하는 것이다. 행동을 취할 때마다 외부 환경에서 보상(Reward)이 주어지는데, 이러한 보상을 최대화 하는 방향으로 학습이 진행된다. 당장의 보상값이 조금은 적더라도, 이러한 보상을 최대화 하는 방향으로 학습이 진행된다.
딥 러닝(Deep Learning)
정의
여러 비선형 변환기법의 조합을 통해 높은 수준의 추상화를 시도하는 기계 학습 알고리즘의 집합.
연속된 층(Layer)에서 점진적으로 학습해나간 다는 점에선 같지만, Deep이란 이름 답게 심층. 즉, 깊은 층을 이루어 학습한다는 것을 의미한다.
오해
일부 저널에서 딥러닝이 뇌철머 작동한다거나 뇌를 모델링했다는 식의 주장이 있지만, 이는 사실이 아니다.
예시
예시의 출처 : 딥러닝이란 무엇인가 - 텐서 플로우 블로그

이미지 안의 숫자를 인식하기 위해 이미지를 어떻게 변환하는지 살펴 볼것이다.

최종 출력에 대해 점점 더 많은 정보를 가지지만 원본 이미지와는 점점 더 다른 표현으로 숫자 이미지가 변환된다. 심층 신경망을 정보가 연속된 필터를 통과하면서 순도 높게(어떤 작업데 해새어 유용하게) 정제되는 다단계 정보 추출 작업으로 생각할 수 있다.
작동 원리

층에서 입력 데이터가 처리되는 상세 내용은 일련의 숫자로 이루어진 층의 가중치(Weight)에 저장되어 있다. 기술적으로 말하면 어떤 층에서 일어나는 변환은 그 층의 가중치를 파라미터(Parameter)로 가지는 함수로 표현된다. 맥락적으로 봤을 때, 학습은 주어진 입력을 정확한 타깃에 매핑하기 위해 신경망의 모든 층에 있는 가중치 값을 찾는 것을 의미한다. 하지만 어떤 심층 신경망은 수천만 개의 파라미터를 가지기도 한다. 이런 경우에 모든 파라미터의 정확한 값을 찾기는 어려울 것이다. 파라미터 하나의 값을 바꾸면 다른 모든 파라미터에 영향을 끼치기 때문이다.

어떤 것을 조정하려면 먼저 관찰해야 한다. 신경망의 출력을 제어하려면 출력이 기대하는 것보다 얼마나 벗어났는지를 측정해야 한다. 이는 신경망의 손실 함수(Loss Function) 또는 목적 함수(Objective Function)가 담당하는 일이다. 신경망이 한 샘플에 대해 얼마나 잘 예측했는지 측정하기 위해 손실 함수가 신경망의 예측과 진짜 타깃(신경망의 출력으로 기대하는 값)의 차이를 점수로 계산한다.
기본적인 딥러닝 방식은 이 점수를 피드백 신호로 사용하여 현재 샘플의 손실 점수가 감소되는 방향으로 가중치 값을 조금씩 수정하는 것이다. 이런 수정 과정은 딥 러닝의 핵심 알고리즘인 역전파(Backpropagation)알고리즘을 구현한 옵티마이저(Optimizer)가 담당한다.
초기에는 네트워크의 가중치가 랜덤한 값으로 할당되므로 랜덤한 변환을 연속적으로 수행한다. 자연스럽게 출력은 기대한 것과 멀어지고 손실 점수가 멀어질 것이다. 하지만 네트워크가 모든 샘플을 처리하면서 가중치가 조금씩 올바른 방향으로 조정되고 손실 점수가 감소한다. 이를 훈련 반복(Training Loop)이라고 하며, 충분한 횟수만큼 반복하면 손실 함수를 최소화하는 가중치 값을 산출한다. 최소한의 손실을 내는 네트워크가 타깃에 가능한 가장 가까운 출력을 만드는 모델이 된다.
AI, 머신 러닝, 딥 러닝의 관계
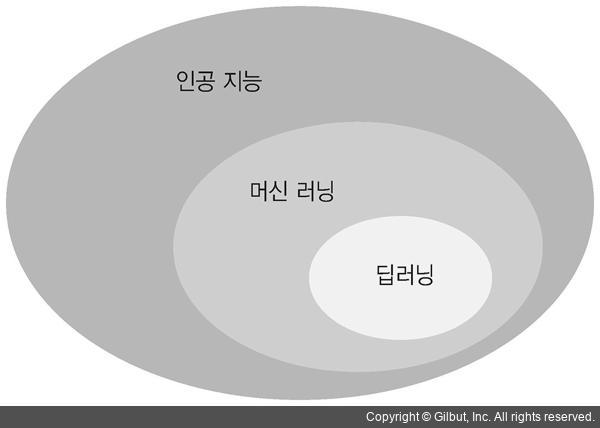
간단히 말해서 딥 러닝은 머신 러닝의 달성하기 위한 방법이고, 머신 러닝은 인공 지능을 달성하기 위한 방법이다. 그래서 아래로 갈수록 포함되는 구조가 되는 것이다.
마치며,
최대한 이해한 바를 축약하기도 했고 예시가 괜찮으면 그대로 옮겨오기 까지도 했다. 아직은 처음 접하기도 하고 밤샌 상태로 읽고 작성하려니 부하가 많이 걸린다.
'Learn > TensorFlow' 카테고리의 다른 글
| TensorFlow 학습 #5 텐서플로우 연산구조 (0) | 2020.09.05 |
|---|---|
| TensorFlow 학습 #4 - 설치 및 실행 (0) | 2020.09.04 |
| TensorFlow 학습 #3 - 머신 러닝 (0) | 2020.08.26 |
| TensorFlow 학습 #2 빅 데이터 간단 학습 (0) | 2020.08.26 |

